在一个增强现实的系统中,其基本构成元素包括以下三个方面:
在 AR系统中,“数字内容增强物理现实”,物理现实是什么,机器设备对环境的感知和认知,一般来说会包含“是什么”、“在哪里”、“状态”几种,只有被机器感知认知,才能进行后续的动作。
我们环境里边,比如人,书本,设备,墙面,花朵,小猫,这些内容一般来说可以被摄像头感知到,RGB 摄像头采集画面的时候,就可以拍摄进来。如果RGB 画面被采集进系统后,还需要使用 AI 对画面进行理解认知,比如一张人脸照片,就需要去人脸库中进行 1:1或者1:n进行识别,进而显示出眼前的人是谁。
除了人脸,比如一本书,一个画面,也会和数据库中的数据库进行比对,从而知道眼前的画面是什么, 比如是一本杂志的封面;这个是比较早期 AR 常用的图像识别技术,一个比较好的 AR需要足够优秀的 AI 技术,才能在不同光照,物理对象形变和污染的情况下,依然有比较好的认知能力。
除了预设数据库进行实景和预设的数据进行对比之外,最近的人工智能技术发展,环境的万可分割(SAM)和语义理解将给机器在环境认知方面提高到一个全新的阶段,万可分割意味着,我们消费 AR内容的时候,部分场景不再需要提前去设置图像库,进而提供了一个“对环境泛在理解”的能力,而非特定提前训练数据集,将一个单一用途的设备变成“万能”的。参见我的另一个文章 (万能画面分割和语意理解对AR的影响 (qq.com))
物理环境对象的理解,目前的技术处理方式分别为:本地识别、云端识别、段云混合识别等方式,而采取的策略受体验现场是否有可靠的网络,终端的计算性能和图集数据库大小等限制;
对物理环境“是什么"的认知,是 AR最基本也是最主要的认知能力;
在 AR系统里,除了眼前对象的语意理解“是什么”之外,还需要解决一个“在哪里"的问题;我们需要把数字内容显示到空间中的某个位置,让我们看到信息就在那里,一个虚实融合的体验。 我们一般用直角坐标系去表达位置关系。
整个系统里中,有两个坐标系:主观坐标系,客观坐标系; 一个是相对于“我“的主观的位置:某个物体显示在我的视觉的什么位置上,比如 一个是物体在哪里
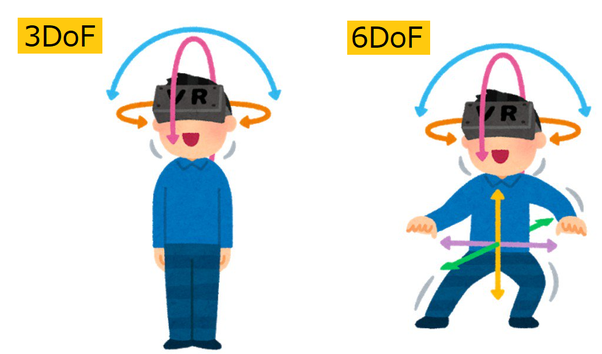
物理环境相对于人的空间关系可以用三轴或者六轴坐标去表达。
在AR的系统中,三轴或者六轴我们可以分为“主观的坐标系”和“客观的坐标系”;主观的坐标系每一次初始化后,是跟第一人称的位恣相关,
物理环境对象的状态可以被数字传感器感知到的内容,比如温度,压强,